Privacy-preserving-and-Efficient-Multi-keywordSearch-Over-Encrypted-Data-on-Blockchain
slug
series-status
status
summary
date
series
type
password
icon
tags
category
摘要
翻译
最近的研究表明,可搜索的区块链不仅可以在加密分布式存储系统上提供可靠的搜索,而且可以确保隐私得到保护。然而,目前的解决方案只关注区块链上加密数据的单关键字搜索。为了将这种方法扩展到多关键字场景,它们基本上会多次执行单关键字搜索,并取得结果的交集。然而,这种扩展存在隐私和效率问题。特别是,处理搜索请求的服务节点将知晓中间结果,其中包括与每个加密关键字相关联的数据。此外,这些多次遍历会导致执行搜索请求的延迟,并额外计算多个集合的交集。最后,服务节点将向数据所有者收取大量费用,以将大量中间结果写入智能合约。在本文中,我们提出了一种基于布隆过滤器的多关键字搜索协议,具有更高的效率和隐私保护。在协议中,布隆过滤器选择的低频关键字将用于在执行多关键字搜索操作时过滤数据库。由于关键字的低频,大多数数据将被排除在结果之外,从而大大降低了计算成本。此外,我们建议使用伪随机标签来促进每个搜索操作仅在一轮中完成。这样,就不会产生中间结果,并且隐私得到保护。最后,我们在本地模拟区块链网络中实施了该协议,并进行了大量实验。
总结
- 目前的研究问题:仅支持区块链可搜索加密的单关键字搜索,对于多关键字场景存在隐私和效率问题,同时也会导致智能合约过多的开销产生。
- 本文的解决方案:基于布隆过滤器的多关键字搜索协议。
- 利用布隆过滤器筛选关键字出现频率
- 仅使用低频关键字过滤数据库
- 为什么仅使用低频关键字过滤数据库?
- 因为最后要搜索的结果是所有关键字搜索结果的交集,因此最后的结果一定完全包含在低频关键字的搜索结果中,所以使用低频关键字过滤数据库并不会导致结果丢失。
- 而使用低频关键字去检索数据库却可以保证得到的数据量是最小的,大大降低了计算成本。
- 为什么使用伪随机标签?
- 为了避免像现有方案一样需要将多个关键字分成多次传输,降低传输次数从而保护数据隐私。
引言
翻译摘要
由于存储和计算资源的日益增加,企业倾向于将数据存储在数据中心而不是本地。由于可能存在敏感信息,例如工会会员资格和健康相关记录,甚至数据中心可能是恶意的,因此在外包之前通常会对数据进行加密。加密反过来又阻碍了数据利用,例如频繁的搜索操作。因此,我们需要引入可搜索对称加密(SSE)技术。SSE是一种允许在加密数据上进行搜索的技术,其中数据所有者不仅加密数据,还加密搜索请求[2]。通过这种方式,数据中心几乎不知道数据的内容。然而,数据中心被假定为在这一领域技术上诚实且好奇[3]。实际上,数据中心有可能是恶意的,并且偏离预定的协议,例如只返回部分结果以节省计算资源。因此,可靠性问题就出现了。
最近,区块链技术[6] [7]显示其解决可靠性问题的潜力。在这些方案中,区块链作为由无信任的对等网络维护的分布式分类账,充当数据中心。存储在区块链和智能合约[8]中的加密数据及其索引用于实现数据存储和数据搜索的功能。由于所有操作都由网络中的所有节点完成,只要大多数节点是诚实的[9],就可以保证结果的正确性。现有的基于区块链的可搜索加密方案[10] [11]仅限于单关键字搜索。它们可以通过多次执行单关键字搜索并取得结果的交集来扩展到多关键字场景。但是,这种扩展存在隐私和效率问题。特别是,中间结果(即与每个单独关键字相关联的数据)将暴露给服务对等端。这种数据泄漏引发了隐私问题。此外,服务对等端必须按顺序处理单关键字搜索请求。由于某些关键字可以出现在大多数甚至所有数据中,多次处理这些关键字的计算成本似乎是一个巨大的负担。大量的中间结果也会导致巨大的财务成本,因为它们由服务对等端写入智能合约。在计算出所有关键字的结果后,服务对等端必须计算结果的交集,这需要额外的计算成本。
本文提出了一种隐私保护和高效的数据管理系统,具有数据库设置、动态更新和多关键字搜索的功能。原始数据库由标识符-关键字对组成,每个标识符可以关联多个关键字。数据所有者可以在设置数据库后动态添加或删除标识符-关键字对,并可以查询与一组关键字相关的所有标识符。数据中心是由多个服务节点组成的区块链网络,这些节点出租计算资源以获取金融报酬。在区块链中部署智能合约来完成数据服务,智能合约是由所有服务节点执行的自动化程序,可以提供可靠的数据服务。此外,SSE被用于智能合约中以保护隐私。最后,我们提出了一种基于布隆过滤器的多关键字搜索协议,可显著降低时延和财务成本。面临的几个挑战如下:
我们面临的第一个挑战是在不违反智能合约中的成本限制规则的情况下建立加密数据库[12]。也就是说,服务节点提供计算资源来维护智能合约的状态。这项工作并非免费,因为智能合约中的每个操作,例如加法和存储到本地磁盘,都需要一定的成本。为了保证智能合约的有效性,单笔交易的成本是有限的,这就是所谓的成本限制规则。在setup阶段,大量加密数据被外包给服务节点。特别是,对于每个标识符-关键字对,我们的算法将生成一个反转和加密的关键字-标识符对以及一个标签来支持多关键字搜索。为了防止setup操作违反成本限制规则,我们设计了一种方法来估计每个标识符-关键字对生成的字节数,并计算单个事务中可以包含的加密数据的数量。然后,我们根据计算结果对加密数据库进行切片,以符合成本限制规则。最后,将加密的关键字-标识符对和标签随机洗牌,以防止数据泄露。
本文的第二个挑战是要设计一个时间和财务有效的多关键字搜索协议。正如之前讨论的,由于会出现大量的中间结果,现有方法在时间延迟和财务成本方面都不够有效。在本文中,我们基于数据库中大多数关键字出现次数较低的观察结果设计了多关键字搜索协议。
总结
- 目前中心化的存储形势存在隐私问题,因此需要引入可搜索加密技术。而数据中心也可能存在作假的情况,因此其可靠性收到了质疑,因此需要引入区块链作为存储结构。但是目前的基于区块链的可搜索加密技术仅限单个关键字搜索,在遇到多关键字场景时往往采用多次查询单关键字求交集的形式扩展到多关键字场景,但是这种扩展存在着很严重的隐私和效率问题。尤其是需要将中间结果(每个关键字查到的结果)暴露给服务对等节点,则会引起隐私问题。并且这种搜索方案需要检索出来大量的数据后再进行一定的运算才能得到想要的结果,这在智能合约上也会导致过高的计算成本问题。
- 针对上述问题,提出了一种隐私保护和高效的数据管理系统,具有数据库设置、动态更新和多关键字搜索的功能。原始数据库由标识符-关键字对组成,每个标识符可以关联多个关键字,并引入了SSE,以及一种基于布隆过滤器的多关键字搜索协议,可显著降低时延和财务成本。
- 面临的两个挑战:
- 在不违反智能合约中的成本限制规则的情况下建立加密数据库
- 设计一个时间和财务有效的多关键字搜索协议
在setup阶段,大量加密数据被外包给服务节点。特别是,对于每个标识符-关键字对,将生成一个加密的关键字-标识符对以及一个标签来支持多关键字搜索。为了防止setup操作违反成本限制规则,设计了一种方法来估计每个标识符-关键字对生成的字节数,并计算单个事务中可以包含的加密数据的数量。然后,根据计算结果对加密数据库进行切片,以符合成本限制规则。最后,将加密的关键字-标识符对和标签随机洗牌,以防止数据泄露。
首先,我们在setup阶段为每个标识符-关键字对生成一个标签。
同时,我们构建一个布隆过滤器来记录数据库中所有的高频关键字。
在多关键字搜索阶段,我们使用布隆过滤器从搜索请求中找到一个低频关键字,并用它来过滤数据库。
请注意,由于所选关键字的频率较低,大多数关键字将被排除在结果之外。
最后,使用每个标识符-关键字对的标签来检查每个候选标识符是否满足搜索请求。
隐私保护和高效链上数据管理方案
翻译摘要
在本系统中,有两个角色,即服务节点和数据所有者。服务节点是区块链网络中的个体节点,他们出租计算资源以获得货币奖励。数据所有者是服务请求者,他们希望外包数据,并享受内容更新和搜索服务。两个角色之间可以发生四种行为,即setup、添加、删除和搜索。每个阶段的正式定义如下。
- 在设置阶段,数据所有者将一系列标识符-关键字$W=\{(id,w_i)|i=1,2,...,l\}$对外包给服务节点,其中每个标识符$id_i \in \{0,1\}^μ$是一个长度为μ的字符串,而每个关键字$w_i\in \{0,1\}^*$是一个不确定长度的字符串。在协议中,选择一个低频关键字,在执行多关键字搜索操作时用于过滤数据库,从而显著降低计算成本。此外,我们提出使用伪随机标签来完成每个搜索操作,以便只需一轮即可完成,从而不产生中间结果,并保护隐私。
- 添加操作是指数据所有者将一组标识符-关键字对
$$
\{id, W_a\}
$$
添加到数据库中,其中$W_a$是一组关键字
- 删除是指数据所有者从数据库中删除一组标识符关键字对
$$
\{id, W_a\}
$$
,其中$W_d$是一组关键字
- 检索时数据所有者发送$W_s=\{w_1,w_2,...,w_k\}$给服务节点来查找所有满足$w\in W_s$和$(id,w) \in W$的搜索结果
系统预览图如下:
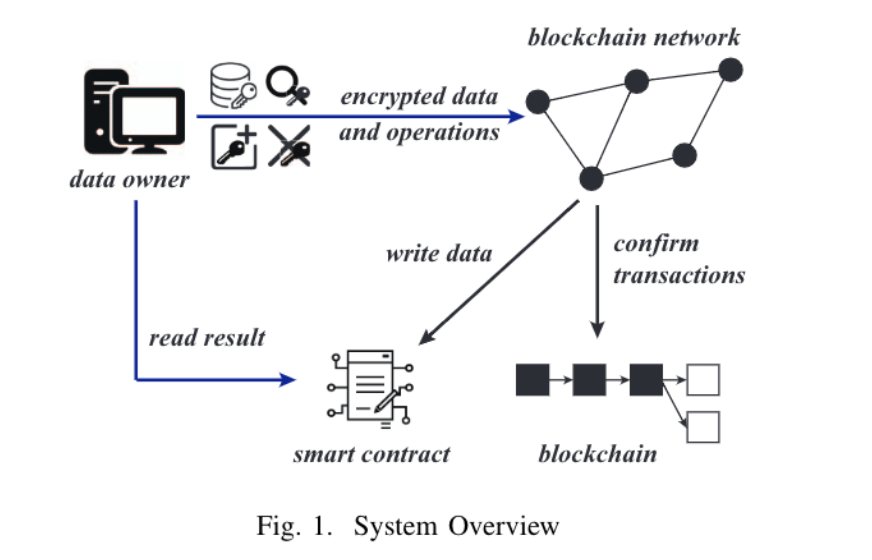
在图1中展示了操作的流程图。当数据所有者执行设置、添加、删除或搜索操作时,他们将发送一个或多个包含加密数据和操作的事务给服务对等端。服务对等端处理事务并将事务打包到区块链中。事务确认进入区块链后,服务对等端将执行将数据写入智能合约的操作。最后,数据所有者可以根据智能合约的状态获得结果。我们设计了隐私保护和可靠的协议来实现以下子节中描述的四个操作。
在介绍具体的四个操作之前,本文首先展示了智能合约的初始化,如算法1所示。智能合约存储了五个变量,包括字典$D_{ori}$,两个集合$S_{del}$和$S_{tag}$,以及两个列表$Flag$和$Result$,用于将来使用。其中,$D_{ori}$用于存储加密的关键字标识符对,$S_{del}$和$Flag$用于支持数据库的动态更新,$S_{tag}$用于支持多关键字搜索,$Result$用于存储搜索结果。最后,智能合约的余额设置为B,即数据所有者存入的金额。未来的操作不能超过B。

数据库setup算法
数据所有者可以使用算法2设置数据库,目的是存储一组标识符-关键字对。首先,数据所有者生成四个秘密密钥K,K +,K-和KT,这四个秘密密钥的大小均为λ,这是一个可调整的安全参数。然后,对于每个关键字w,从预定义的伪随机函数(PRF)[13] F和秘密密钥K中派生出两个密钥K1和K2。密钥K1用于派生关键字的伪随机标签,而密钥K2用于加密标识符。使用关键字w,我们可以获得与w相关联的所有标识符,表示为集合$W_w$。然后,我们遍历$W_w$中的标识符id。对于每个id,使用密钥K1将(PRF) F应用于计数器c以生成伪随机标签l。同时,我们使用K2使用K2加密id并获得加密标识符d。然后,我们将关键字标识符对$(l,d)$添加到列表L中。总之,我们将每个标识符关键字对反转为加密的关键字标识符对,并将结果存储在列表L中。此外,我们使用秘密密钥KT连续应用(PRF) F在w和id上生成每个标识符关键字对(id,w)的唯一标签。标签累积到列表$L_{tag}$中。注意,标签用于多关键字搜索。
数据所有者必须在加密后将数据库发送给服务对等方。但是,由于智能合约中的成本限制规则,加密数据库必须在发送之前进行分片。通常,智能合约中的每个操作都需要特定的成本,每个发送到智能合约的交易都有一个成本限制。因此,每个事务可以附加的数据数量有限。在我们的协议中,每个标识符-关键字对生成的数据被设计为有界,即关键字-标识符对和标签。如果(PRF) F是固定的,例如HMAC-SHA256 [14],关键字-标识符对和标签的大小将是固定的,例如512位和256位。
我们可以计算一次交易中可处理的标识符-关键字对的最大数量δ。假设(PRF) F将消息摘要为δf位,单次交易中可存储的位数为δt,则δ的值应为δt/(3δf)。在本文中,一次交易最多可存储10KB,HMAC-SHA256作为PRF。因此,δt等于80,000,δf等于256,δ计算为104。当计数器达到δ时,我们将列表L和Ltag洗牌,并将包含它们的设置交易发送给服务对等。洗牌L和Ltag的原因是为了防止服务对等推断与数据相关的任何信息。
服务节点的角度来看,他们收到几笔设置交易,以及两个列表$L$和$L_{tag}$。对于每笔交易,他们会枚举列表L中的元素$(li,di)$,并将其添加到字典$D_{ori}$中,其中$l_i$作为键,$d_i$作为值。之后,他们将$L_{tag}$中的所有元素存储到智能合约中的集合$S_{tag}$中。我们可以看到,数据存储在智能合约中的无序数据结构中,即字典和集合。因此,设置协议对收到的交易顺序具有免疫力,这是一个显着的特征。

多关键字搜索算法
上文中描述了设置、添加和删除的协议,以实现数据的动态可靠的存储和更新。本节中,我们描述了在加密数据库上进行多关键字搜索的协议。首先,我们介绍了构建布隆过滤器的方法,其中包括数据库中经常出现的关键字。在算法2中,我们创建了一个字典Dkey来计算每个关键字的出现次数,关键字w的出现次数定义为:
$$
F(w,W)=|\{(id_i,w)|(id_i,w)\in W\}|
$$
如果一个关键字出现在按照非递减顺序排序的$\{w|w\in W\}$的前百分之β中,则会被定义为高频关键词,如果一个关键词非高频关键词则被定义为低频关键词。
我们使用哈希函数H将高频关键字w哈希成α位的0/1字符串H(w),并使用H(w)对bf进行位或操作,从而形成包含所有高频关键字的布隆过滤器bf。α和β是需要调整以使布隆过滤器有效的参数,α值越大,数据所有者的存储负担越大,但判断高频关键字时的误报率越低;而β值越大,误报率越高,但如果是真正的正确结果,则成本越低。本文中,我们将α和β设置为8000和10%,足以处理多达9.1M个标识符-关键字对的数据库。
布隆过滤器设置完成后,数据所有者可以使用它来在搜索请求中的k个关键字中找到任意低频关键字。如果关键字的哈希值不等于将其与bf进行位与操作的结果,则该关键字必须是低频的。如果找到这样的低频关键字,我们将其与多关键字搜索请求中的第一个关键字进行交换。而如果在k个关键字中没有低频关键字,那么第一个关键字将保持高频。请注意,如果操作之前第一个关键字是低频的,我们不会将其设置为高频,因为布隆过滤器不会发生真正的负面判断。
数据所有者现在开始生成加密搜索请求。数据所有者将使用秘密密钥K,K+和K-来生成三个伪随机标签K1,K+1和K-1以及两个对称密钥K2和K+2,用于第一个关键字w1。同时,使用秘密密钥KT为每个关键字ki生成一个标签,其中i从2到k。这样,将生成一个包含三个伪随机标签,两个对称密钥和k-1个标签的加密搜索请求,并发送给服务节点。
当收到数据所有者的搜索请求时,服务节点将从第一个关键字开始,并获得一组候选标识符。特别是,他们使用伪随机K1和K + 1在智能合约中遍历$D_{ori}$。然后,服务对等使用K1或K + 1在加密后累积$D_{ori}$的键字段中存在的所有计数器。之后,服务对等使用相应的对称密钥添加解密后对应于累积计数器的标识符。最后,我们同时处理删除集和其他k-1个关键字。对于解密后的每个标识符id,我们检查使用伪随机删除标签K-1加密的id的结果是否在$S_{del}$集中,以及应用(PRF) F到id后的任何k-1个标签是否不在标签列表$S_{tag}$中。如果任何两个条件都满足,则id将被排除在结果之外。
最后,对时间复杂度和资源消耗进行计算。传统方法需要O(k·l+k·n·log n)的时间延迟和O(k·n)的财务开销,而我们的方法只需要O(l+k·β·n)的时间延迟和O(n)的财务开销。实验表明,β可以小到10%,大大降低了时间复杂度,而且只有最终结果会被写入智能合约,从而保护了隐私。

实验结果
翻译摘要
我们使用Python 2.7实现数据库设置、动态更新和多关键字搜索操作,使用PYCRYPTODOME包中的HMAC-SHA256实现PRF,使用PYBLOOM包实现布隆过滤器[16]。我们在运行Ubuntu 16.04.5的笔记本电脑上运行数据所有者和服务对等方,具有16GB RAM和两个Intel i7-6500U核心。服务节点形成本地模拟区块链网络,接受数据所有者的请求,并运行智能合约。为了关注我们协议的性能,我们将块生成时间设置为0,这意味着复杂网络拓扑的影响不会被考虑在内。
我们在实验环境中进行了大量实验,使用的是Eron电子邮件数据集[17],其中包含517K封电子邮件。原始数据库是从数据集中生成的,每封电子邮件被视为一个新的标识符id,每个电子邮件中的单词经过小写处理后被视为与id相关联的关键字。通过这种方式,我们得到了一个由517K个标识符、622K个不同关键字和9.1M个标识符-关键字对组成的数据库。
单个关键字搜索
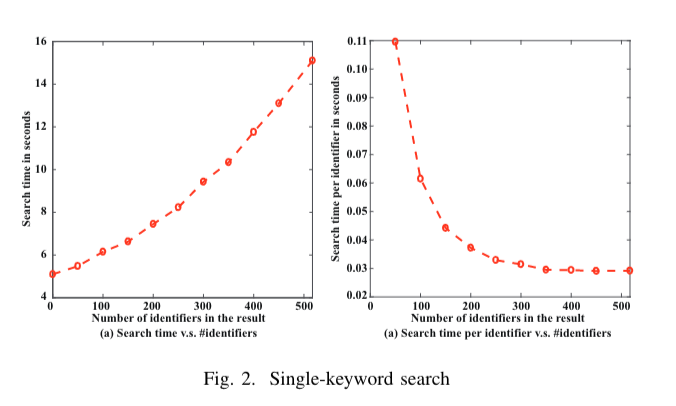
单关键字搜索操作中,数据所有者的时间消耗可以忽略不计,因为只涉及几次对称加密操作。在服务对等方,需要两次遍历字典$D_{ori}$,并将数据写入本地状态。我们对具有不同出现次数的关键字进行搜索实验。结果如图2所示。当没有匹配的标识符时,需要5.12秒,这是遍历字典$D_{ori}$的时间。此外,当所有标识符都与关键字相关联时,需要15.10秒。随着结果中标识符数量的增加,搜索时间每个标识符减少。原因是大量标识符可以平均遍历字典的时间。
多关键字搜索
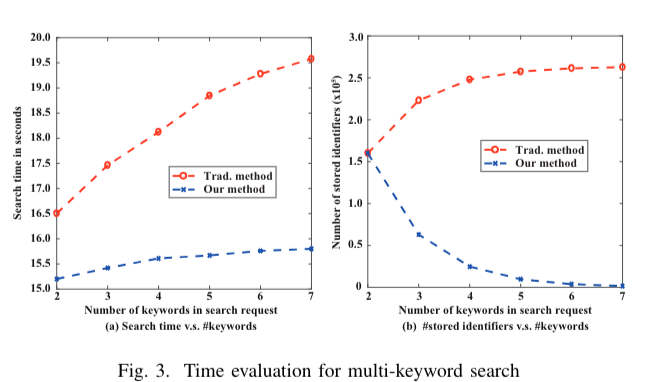
本文提出了一种基于布隆过滤器的多关键字搜索协议,以提高效率和保护隐私。我们对2到7个关键字进行了多关键字搜索实验,将传统方法(或交集方法)与我们的方法进行了比较。传统方法是多次应用单关键字搜索,并将结果的交集作为最终结果。我们的方法中,我们将β设置为10,因为分析后发现,不超过0.05%的关键字出现在至少10%的标识符中。我们运行了50次实验,并将时间和财务开销的比较结果如图3所示。注意,由于关键字是随机生成的,因此实验中包括极端情况,例如所有关键字都具有高频率。
我们的研究表明,时间开销方面,交集方法受关键字数量的显著影响,因为当关键字数量增加时,需要计算更多集合的交集。对于我们的方法,多关键字搜索的时间不会随着关键字数量的增加而变化太多。原因是,在使用第一个关键字过滤数据库后,候选标识符很少。此外,在一个关键字的情况下,只会增加一次标签比较操作的计算负担。平均而言,我们的方法在时间效率方面优于交集方法14.67%。在财务开销方面,搜索操作的主要财务成本在于数据存储,因为与其他操作相比,数据存储占主导地位。因此,我们将写入智能合约状态的标识符数量视为财务成本。对于交集方法,当关键字数量从2增加到5时,存储的标识符数量增加约60%,而5个或更多关键字的情况下几乎不变。原因是相同的5个或更多关键字的标识符很少。随着关键字数量的增加,我们的方法的财务成本会减少,因为我们只调用智能合约并写入一次结果。此外,过滤关键字数量增加时,合格标识符的数量会减少。平均而言,我们的方法在财务成本方面优于交集方法59.96%。
Loading...